Evolve Logical Data Model
In a typical workflow, you are evolving LDM in time. For example, when you add a new table to your database, and you want to utilize it in your insights, you have to update PDM and LDM accordingly.
Generally there are three approaches. All approaches require updating PDM, go to Physical Data Model to learn how.
- Update LDM manually in Modeler application
- Auto generate new LDM in Modeler application
- Auto generate new LDM by utilizing the related API
We are going to describe here the first two approaches, the third one is described in the article Auto Generate LDM.
Difference between approaches
Both approaches can end up with the same model. Update LDM manually, if Auto generate new LDM would rewrite your manual changes, or if you want to add a complex LDM design, which cannot be auto-generated.
Every time you update the LDM, you have to publish it to the workspace before you can utilize changes in analytical applications.
Use case - extend Model by Shared Dimensions Region and State
We are going to evolve the Demo model used in Getting Started.
As you may already realize, the model is not fully aligned with best practices described in root page of this section.
For example, there are attributes State and Region in many datasets.
They are not defined as separate dimension datasets, which could be shared by all fact tables.
Insights utilizing facts (or measures based on them) from both Order lines and Campaign Channels fact tables cannot be sliced by Region or State attributes.
Info
Region and State attributes are denormalized in the database.
This may still be valuable from performance point of view.
E.g. if you want to slice facts from Order lines by State and you want to get only states with at least 1 order line,
it is valuable to use Order lines.State attribute, because in underlying database no JOIN operation has to be executed.
Alter relational model in the database
We are going to alter relational model in the embedded PostgreSQL database.
Use your favorite IDE for working with databases, e.g. Dbeaver.
If you prefer command line, you can utilize psql from inside the container:
# Update "some-gooddata" to the name of container you chose during startup of platform
docker exec -it some-gooddata bash
psql -U demouser -d demo
Connect to the database using same credentials, which we used during registration of the related data source entity:
- username = demouser
- password = demopass
The following SQL script creates two new tables regions and states. Tables are populated by data from already existing tables.
set search_path to demo;
create table regions (
region varchar(128) not null,
constraint pk_regions primary key (region)
);
create table states (
state varchar(128) not null,
region varchar(128) not null,
constraint pk_states primary key (state),
constraint fk_states_regions foreign key (region) references regions (region)
);
insert into regions
select region from customers union select region from campaign_channels;
insert into states
select state, region from customers union select state, region from campaign_channels;
alter table customers add constraint fk_customers_states foreign key (state) references states (state);
alter table order_lines add constraint fk_order_lines_states foreign key (state) references states (state);
alter table campaign_channels add constraint fk_campaign_channels_states foreign key (state) references states (state);
Info
There are alternative ways how to prepare new regions and states tables.
Solution depends on what you prefer and also on amount of data in related tables:
- Create views on top of the existing tables
- Most simple solution, but negatively affects performance of related reporting, DISTINCT regions / states would have to be calculated in each report “on-the-fly”.
- Utilize features related to your database, like materialized views or aggregated projections
- You can find more details in Supported Databases
- Extend you ETL and fill the new tables in it
Update PDM and Manually Update LDM
Let’s say we cannot utilize Auto Generation of LDM, e.g. because we manually updated the Demo model in the past, and we do not want to lose these changes.
- Create datasets
StatesandRegions - Add attribute ID into both datasets
- Set ID attributes as primary keys
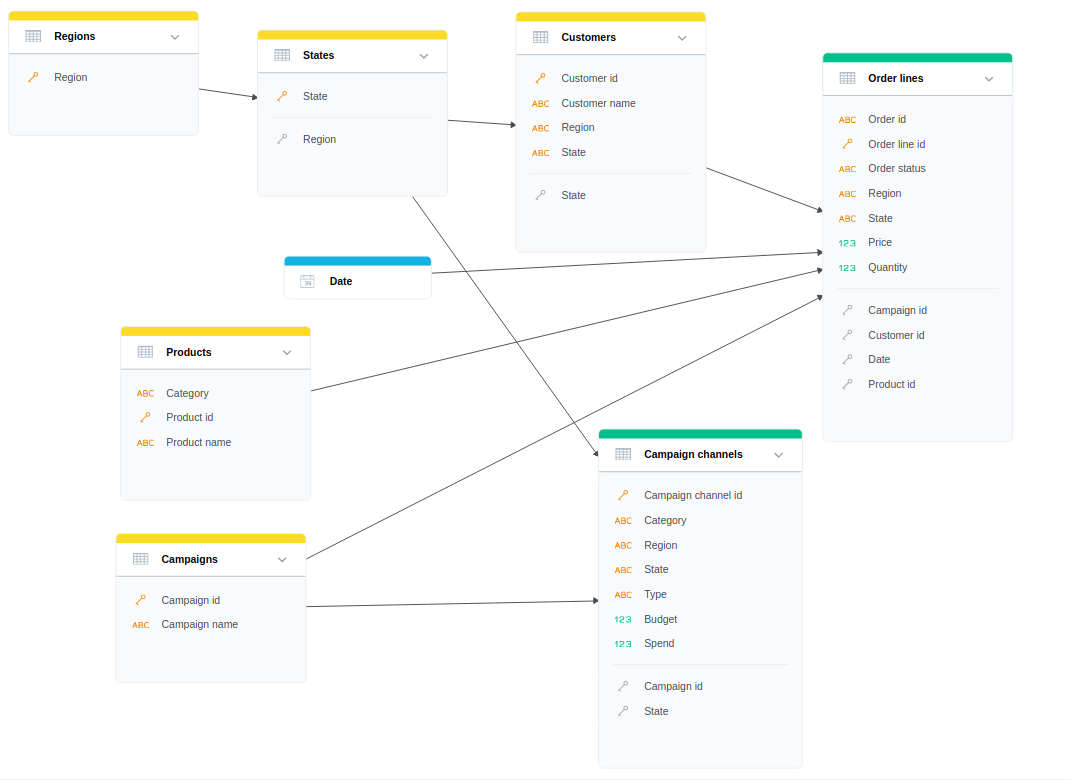
- Create relations from
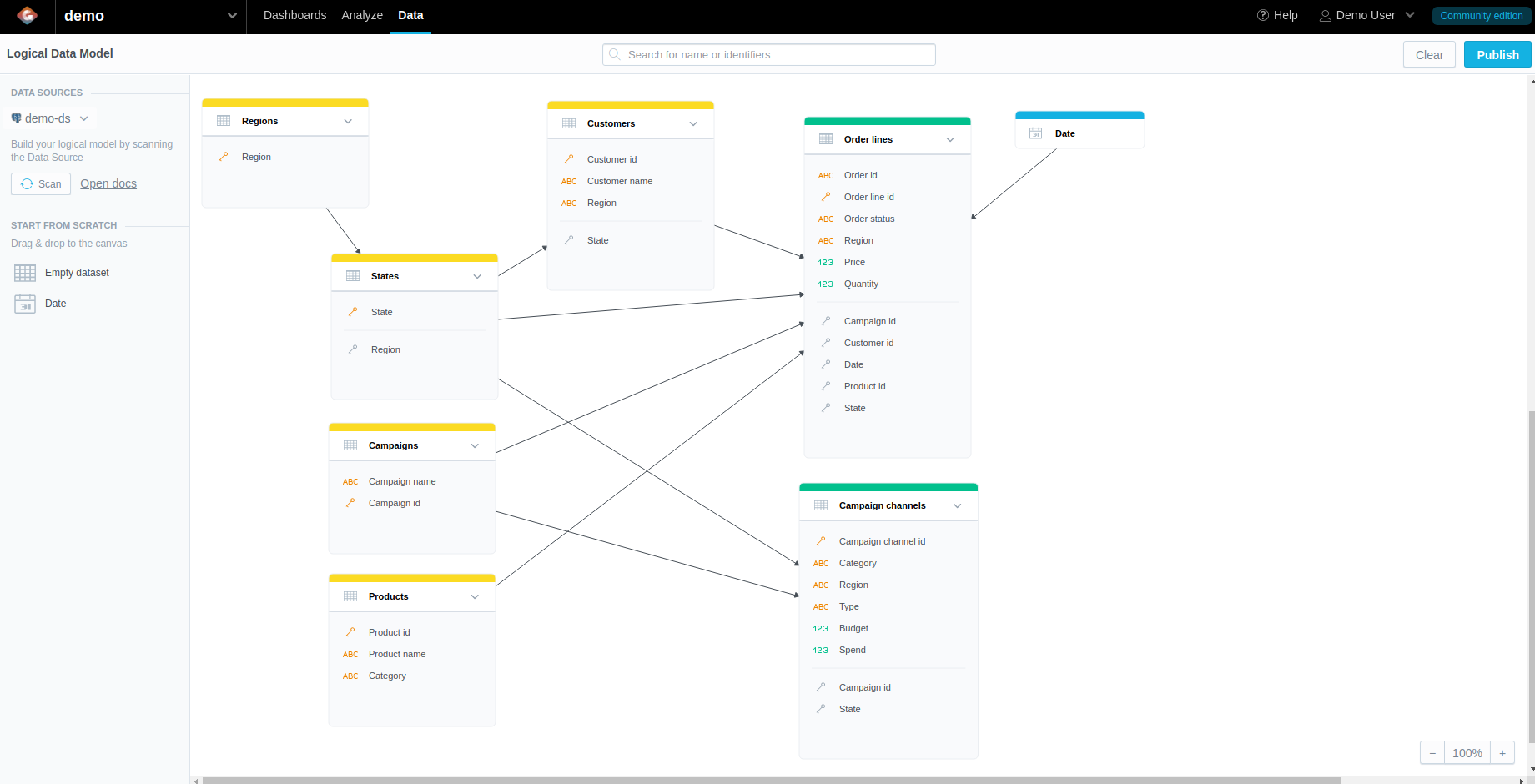
RegionstoStatesand fromStatestoCustomersandCampaign Channels. We should end up with the model below.Info
The model visualization is refactored to be aligned with best practices, relations are going from the left to the right, so now it is obvious, what can be analyzed in insights - generally facts (or measures based on them) on the right by attributes on the left.
- Scan model without generating datasets. It is fully described in How to Scan Physical Data Model.
- Map
StatesandRegionsto new tables we created in the previous chapter, including the Foreign key inStates.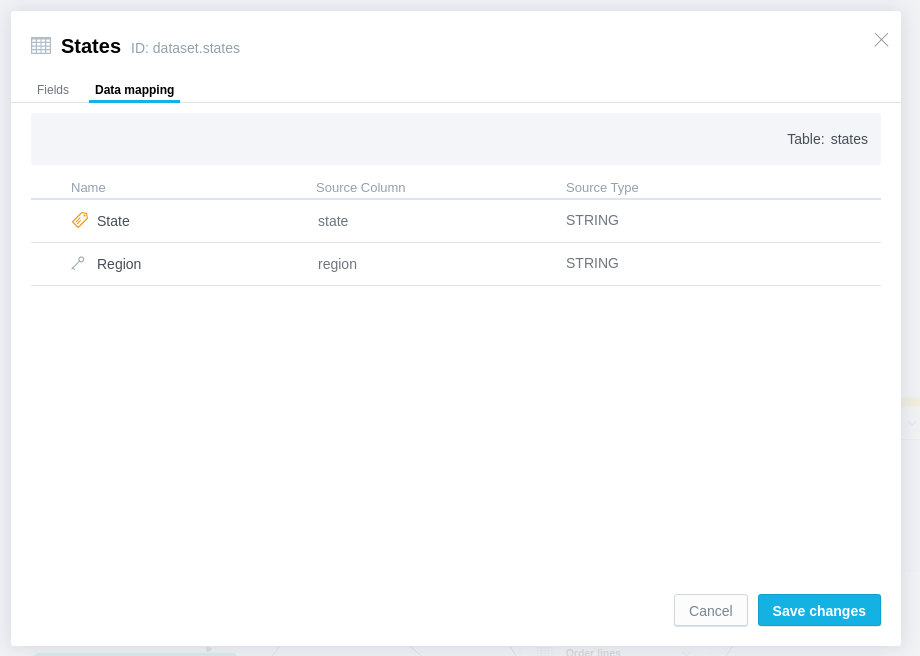
- Map new references to
Statesdataset inCustomersandCampaign Channels.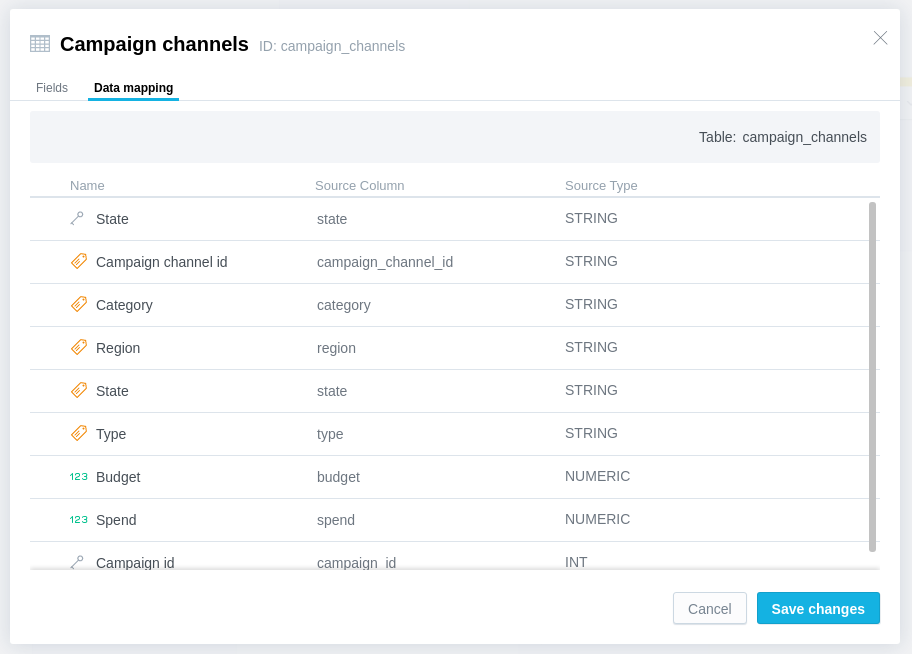
Consider if you need to keep State and Region attributes in datasets Customers and Campaign Channels.
They may be useful from performance point of view (prevent JOINs between underlying tables),
but they have limited usage (only regions/states are displayed, which have at least one record in the related table).
Update PDM and Generate New LDM
In this case, because we defined primary and foreign keys, we can still utilize Auto Generation of LDM.
Use Replace Scan mode to fully replace already stored PDM, otherwise you would end up with invalid mapping between LDM and PDM.
The result model:
Publish the Model
Go to Publish Logical Data Model to learn how to publish model.
Utilize New Model in Analytical Designer
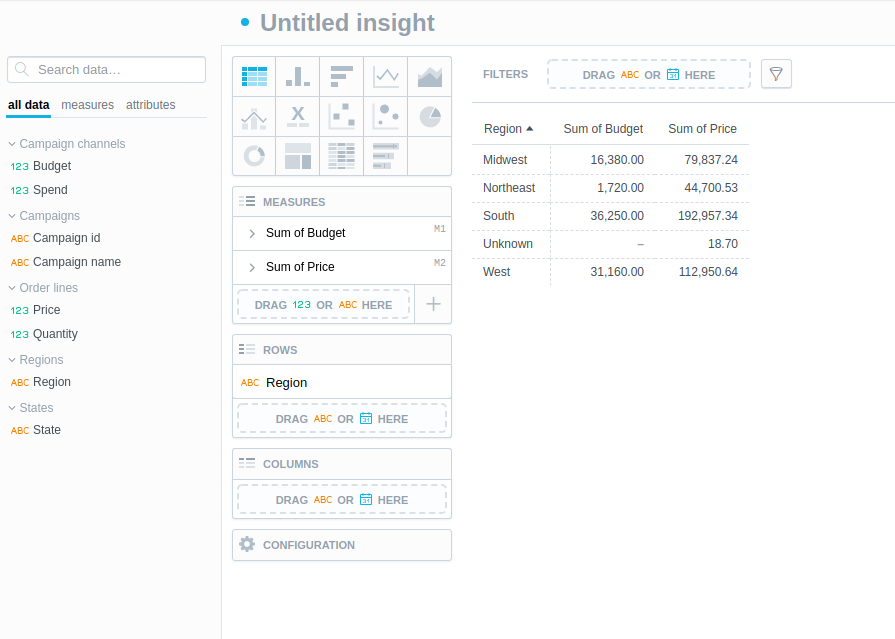
Now let’s evaluate the new model in Analytical Designer.
Create an insight containing two measures Campaign Channels.Budget and Order lines.Quantity.
Now you can slice them both by Regions.Region: