GoodData.CN Microservices
GoodData.CN is built as a collection of microservices, each responsible for a specific function within the platform. These services run in their own Kubernetes pods and communicate through a Kubernetes-based infrastructure, enabling independent scaling, resilience, and efficient resource management.
Below is a list of all microservices that constitute GoodData.CN, along with an overview of their roles. The microservices are grouped conceptually based on their domains within the GoodData.CN architecture. Note that these categorizations are purely conceptual and do not reflect any physical grouping in the installation.
API
The API services consist of:
afm-exec-api
The AFM stands for attributes, filters, and metrics. The service serves as the gateway for report computation and related use cases. It allows REST clients to define report executions more easily than by creating complex metrics. The service handles the following use cases:
- Report execution: Computation of Reports
- Valid objects: Returns compatible Logical Data Model (LDM) entities (attributes, facts, metrics) based on the current context (AFM).
- Label elements: Returns label values (distinct values in the mapped table column).
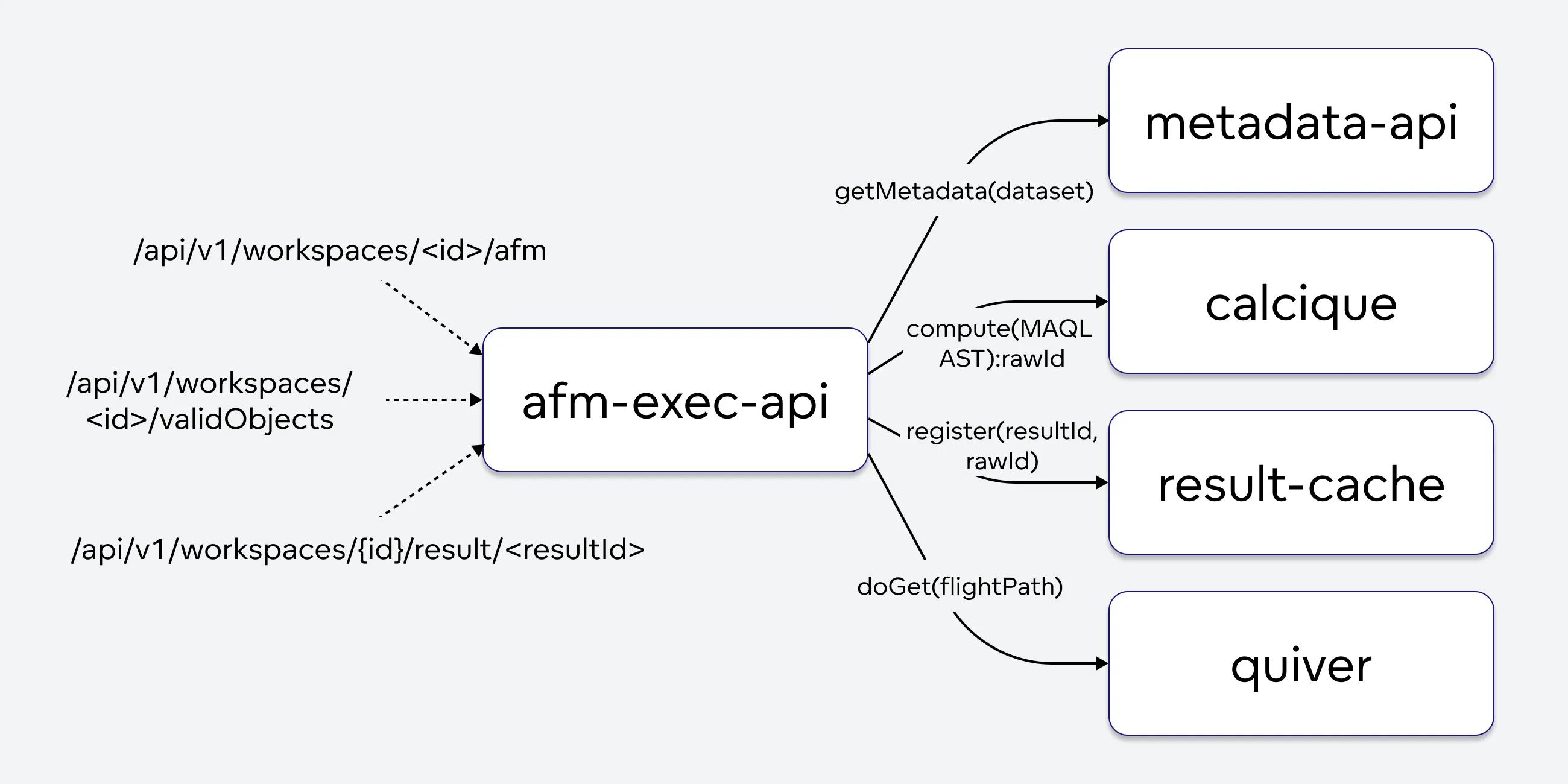
The service utilizes the MAQL parser, collects relevant metadata from the metadata-api service, and transforms AFM requests into MAQL ASTs. These ASTs can be used by the calcique to generate corresponding SQL statements.
api-gateway
The API Gateway functions as a reverse proxy designed to manage and secure HTTP requests and responses. Its primary role is to enhance the responses from the frontend applications (such as dashboards and analytics) by adding Content Security Policy (CSP) headers. This CSP configuration is a combination of static settings defined during deployment and dynamic settings obtained from the organization’s configuration through the metadata-api service.
The API Gateway is configured through Helm charts and by interacting with the metadata-api service. This interaction allows it to retrieve the necessary CSP configurations tailored to each organization, requiring no special actions beyond those used for other microservices in the platform.
auth-service
The Auth Service manages authentication based on OAuth 2.0 using the OAuth2 Library. It provides user context, including information about the authenticated user and their organization, essential for API clients. To enhance security, session data (Access and ID tokens) is stored as encrypted HTTP cookies.
Key features of the Auth Service are:
- Authentication:
- Handles login, logout, and user profile proxy for all microservices.
- OAuth 2.0 authentication is enabled by default to ensure seamless microservice integration.
- License Proxy:
- Validates API calls against the Tiger license, ensuring compliance before processing requests.
- Optional Dex OIDC Provider Proxy:
- Provides a simple CRUD interface for user management via a local OIDC provider (Dex).
- This is disabled by default and can be enabled through configuration.
The gooddata-server-oauth2 library is integrated into all public microservices. Unauthenticated requests are redirected to the auth-service for processing, triggering an authentication flow with either Dex or an external OIDC provider. The custom library also enables dynamic runtime configuration of the OIDC provider through metadata.
The OAuth2-based login is based on multiple HTTP redirects which, after the successful authentication, end up with a granted Access Token needed for accessing any backend resource. This sequence diagram describes how it works with JavaScript clients.
export-controller
Export Controller is responsible for exporting visualizations as PDF, XLSV and CSV files.
The microservice exposes REST API endpoints to:
- Initiate tabular export (CSV, XLSX, HTML, PDF) of already calculated insight by passing it’s executionResult ID or tabular export (HTML, PDF) of visualization object by passing it’s ID
- returns exportId
- Initiate visual export of dashboard by passing it’s dashboard ID → returns exportId
- Pickup the export result identified by exportId
Once an export request is received, the service creates a new apiToken with short TTL and passes apiToken together with export information to:
- tabular-exporter using gRPC channel
- gRPC channel response contains exported data in a requested form
- visual-exporter-service using REST API call
- REST API response contains exported PDF data which are streamed directly to pdf-stapler-service using gRPC channel to add headers and footers. gRPC channel response contains stapled PDF data
Export is saved to configured export storage (currently supported storages: S3 bucket, local filesystem).
When controller receives export pickup request, it checks the status using export-id:
- export is not ready yet -> HTTP 202
- export ready - returns export data -> HTTP 200
- export failed due to user error / export not found -> HTTP 404
- export failed due to server error -> HTTP 500
metadata-api
The Metadata API service manages all GoodData platform metadata, including report and metric definitions, and stores it in a PostgreSQL database. It exposes a public REST API for interacting with this metadata, organized into three main groups:
/api/entities: CRUD operations following the JSON:API standard./api/layout: Management of declarative documents, such as Logical Data Models (LDM), workspaces, or even entire organizations./api/actions: Specific RPCs, like generating a Logical Model.
The service plays a critical role in the platform, as it must notify the calcique and sql-executor microservices about specific metadata changes. These microservices cache some metadata, so the Metadata API uses Apache Pulsar for asynchronous notifications to ensure they stay up-to-date.
For real-time metadata requests, the service provides dedicated gRPC calls to support microservices that require immediate access to metadata.
Additionally, the service handles an exceptional API for storing data sources. When metadata related to data sources is stored, the Metadata API calls the SQL Executor to validate jdbcUrls, with validations specific to each data source type.
scan-model
The Scan Model Service allows users to scan data sources and test their availability. It processes input requests that configure the scan, specifying details such as the data source, schema, and table prefixes. The service outputs a Physical Data Model (PDM), which is a declarative definition of the scanned data source’s structure. This PDM can then be stored in the metadata-api service for further use. Users can create a Logical Data Model (LDM) in tools like the LDM Modeler app and map it to the PDM.
The service offers two APIs for testing the availability of data sources:
- Test registered data sources: For sources already registered in the metadata-api.
- Test unregistered data sources: For sources that have not yet been registered, allowing for a preliminary check.
For these tests, the input request must include a full definition of the data source, such as the jdbcUrl.
The Scan Model Service forwards requests to the sql-executor microservice, which is the only service that directly communicates with data sources. Once the sql-executor returns the results in an internal format, the Scan Model Service transforms these results into the PDM format.
Frontend
The frontend services consist of:
- UI Applications which consist of:
- analytical-designer
- dashboards
- home-ui
- ldm-modeler
- measure-editor
- apidocs
- web-components
UI Applications
UI Application are a service suite for serving web content. Each of the services in this suite run an NGINX server that serves the web frontend for a particular URL:
| Microservice | Serves content for |
|---|---|
| analytical-designer | <your-hostname>/analyze/ |
| dashboards | <your-hostname>/dashboards/ |
| home-ui | <your-hostname>/ |
| ldm-modeler | <your-hostname>/modeler/ |
| measure-editor | <your-hostname>/metrics/ |
These services do not directly communicate with other services. Instead, the web applications themselves, based on user actions, make use of the API services to retrieve data and perform necessary actions.
apidocs
The Apidocs service provides documentation for the GoodData.CN APIs under the URL <your-hostname>/apidocs. It serves Swagger-based API documentation generated directly from the codebase.
web-components
The Web Components microservice runs an NGINX server that serves the necessary JavaScript file for embedding GoodData web components into external web applications. The files can be accessed at <your-hostname>/components/<some-component-id>, see Embed Visualization Using Web Components. This service does not directly interact with other microservices; it simply delivers the JavaScript library used in client applications for embedding GoodData functionality.
Compute and Cache
The compute and cache services consist of:
- automation
- calcique
- db-pgpool
- db-postgresql
- etcd
- redis-ha-server
- result-cache
- sql-executor
- Quiver which consists of:
- quiver-cache
- quiver-ml
- quiver-datasource
- quiver-xtab
automation
Automation microservice is responsible for scheduling and alerting.
The automated tasks are persisted in Postgres. Once the condition is met to execute an action, this service communicates with the other services to complete the task (for example export-controller for scheduled exports). Once there is a result (success/fail), it communicates the result to a notification channel (for example a webhook endpoint).
Task execution flow:
- A trigger condition is met (for example a scheduled time or an alert threshold on a metric)
- Launch a coroutine to handle execution of all actions (for example generate 2 dashboard exports)
- Wait for action completion, or timeout.
- Send notification with the results.
calcique
The Calcique Service is the core component of GoodData, built on the Apache Calcite framework. It is responsible for manipulating SQL trees and generating valid SQL statements for all supported data sources. The service is implemented in JVM (Kotlin) and is a key successor to the former AQE (Analytical Query Engine).
Key Functions:
SQL Generation: Calcique generates SQL statements based on multiple inputs, including:
- MAQL AST generated by the afm-exec-api service.
- Metadata and definitions retrieved from the Metadata Service.
- Cached Logical Data Models (LDM) and Physical Data Models (PDM).
- Real-time metric definitions collected from metadata.
Caching and Optimization: Inputs like MAQL AST, LDM, and PDM are cached by Calcique, with cache invalidation managed through Apache Pulsar. If caching is enabled for a data source (
dataSource.enableCachingisTrue), Calcique generates N-1 Create Table As Select (CTAS) statements and one SELECT statement, materializing pre-aggregations directly in the data sources. These pre-aggregations can then be reused by other reports, optimizing query performance.Raw ID Management: The service generates a
rawIdusing a combination of the MAQL AST, model versions (LDM, PDM, metrics), and thedataSource.uploadId(which represents the version of data in data sources, typically changed by the customer’s ETL processes). ThisrawIdis registered in the result-cache. If therawIdis already registered, Calcique skips SQL generation and execution, returning an “ALREADY_REGISTERED” status to afm-exec-api, which then triggers only the post-processing of the raw result into the final result.Integration with SQL Executor: If the
rawIdis not registered, Calcique pushes the generated SQL statements into a dedicated Apache Pulsar topic. The SQL Executor Service then pulls these statements from the topic for execution.
Calcique plays a crucial role in ensuring efficient and optimized query generation and execution across all supported data sources within GoodData.
db-pgpool
DB-Pgpool is a middleware service that connects PostgreSQL databases with other microservices in GoodData.CN. It provides high availability and load balancing for database connections, ensuring that the platform’s backend services can efficiently read from and write to the PostgreSQL database.
db-postgresql
The DB-PostgreSQL service manages the internal PostgreSQL database used by GoodData.CN. This database stores metadata, user data, and other critical information. The service is typically deployed in a highly available configuration, ensuring that data remains accessible even in the event of hardware failures.
etcd
Etcd is a key-value store used by GoodData.CN to coordinate distributed processes and manage configuration data. It plays a vital role in ensuring consistency and reliability across the platform, particularly for services that require real-time configuration updates or state synchronization.
Etcd is used solely by quiver microservices. Maximum amount of cache’s metadata being stored in ETCD pods is configured by limitFlightCount (default is 50000).
redis-ha-server
Redis-HA-Server is a highly available Redis instance used by GoodData.CN to store ephemeral data, such as session information, caching metadata, and intermediate query results. This service ensures that frequently accessed data is available with minimal latency.
result-cache
The Result Cache receives raw results from the sql-executor, streamed via gRPC, and stores them under a rawId key in Redis. After storing the raw results, the service initiates a process called cross-tabulation, which involves pivoting, sorting, and pagination (dividing results into multiple pages). This cross-tabulation process is managed asynchronously by sending requests to a dedicated Pulsar topic. The service also listens to this topic, processes the requests, and performs the necessary transformations on the raw results.
Once the cross-tabulation is completed, the processed results are stored under a resultId key in Redis, making them accessible for clients via the afm-exec-api. Clients poll for results using the resultId, and once the result is available, it is returned to the client. If the result is not available within a certain timeframe, a timeout may occur.
The service manages its file storage (with a default limit of 1GB) by evicting the least recently used caches when the storage limit is reached. Redis is utilized not only to store the cached raw and processed results but also to maintain metadata about these cached data in FlexQuery.
sql-executor
The SQL Executor serves as the gateway to data sources within the system, responsible for executing queries, retrieving results, and managing database connections. It plays a critical role in several key processes, including report execution, scanning database metadata (schemas, tables, columns, constraints), and testing the correctness of data source configurations.
The service connects to registered data sources as needed, utilizing connection pooling to optimize performance. For JDBC connections, it employs HikariCP, caching connections per organization to enhance efficiency. For BigQuery, the Google Cloud BigQuery Client for Java is used.
SQL statements are received from a dedicated Pulsar topic, populated by the Calcique service. Once executed, the report results are streamed through gRPC to the result-cache service, where they are stored and made available for further processing.
In addition to executing queries, the SQL Executor is also responsible for storing results in the cache and managing the overall connection pooling, ensuring that the system maintains optimal performance when interacting with various data sources.
Quiver
Quiver is a service suite for reading, writing, manipulating, and managing data caches from customer data sources. Quiver:
- Stores raw caches: raw data from SELECT queries, used for further computation.
- Stores result caches: data from cross-tabulations, served via the AFM Result API and displayed in the UI.
- Stores element caches: raw data served via the AFM Valid Elements API, often shown in attribute filter drop-downs.
- Computes result caches: using Quiver’s dataframe service for cross-tabulation.
- Analyzes CSV files and runs SQL queries on various data sources.
- Quiver’s caching is highly configurable and supports hierarchical caching, ensuring data durability using systems like S3. However, caches are not permanent and can be invalidated or removed according to policies.
The Quiver suite consists of four services:
| Microservice | Function |
|---|---|
| quiver-cache | Responsible for storing and fetching of data caches. Every one of these pods pod can hold up to cacheCountLimit caches (default is 5000) in memory/fs in sum. |
| quiver-ml | Responsible for crosstabulation computation. |
| quiver-datasource | Responsible for running SQL queries and connecting to the Quiver-handled datasources and is currently only used for CSV data sources. (disabled by default) |
| quiver-xtab | Responsible for certain ML operations on top of the raw data stored in Quiver. |
The Quiver services themselves are stateless. All important state is stored in etcd and the Quiver services load it at startup and then keep themselves up-to-date using etcd watches.
Export
The export services consist of:
pdf-stapler-service
The PDF Stapler Service provides functionality for assembling and customizing PDF files generated by the platform. It handles tasks such as adding headers, footers, and watermarks to exported PDFs, ensuring that documents meet the required formatting standards.
tabular-exporter
Tabular Exporter is a microservice that converts visualization result data into CSV, XLSX, HTML, or PDF formats. The service exposes a gRPC endpoint to receive export requests, which include a visualization executionResult ID or visualizationObject ID (the latter is supported only for HTML and PDF exports).
The service is Python-based and uses the GoodData Pandas library, to fetch visualization result data and store them to pandas data frame.
The service also uses gooddata-formatter python library to apply custom formatting. Another styling and formatting is applied directly with pandas dataframe styler.
Finally, the service generates the CSV, XLSX, or HTML export using pandas’ native functionality and streams the result back to the gRPC client. For PDF exports, the service converts the HTML output using the WeasyPrint Python library.
visual-exporter-service
The Visual Exporter Service is composed of four microservices: three that handle PDF export requests and one that manages the stapling of PDF files:
visual-exporter-serviceA Kotlin-based microservice that exposes a REST API endpoint for accepting PDF export requests. These requests are provided in the form of a URL to be “snapshotted” along with a temporary API token for authentication. The service communicates via WebSocket with a headless Chromium instance running in the
visual-exporter-chromiumcontainer and orchestrates the PDF export using Chromium’s native export capabilities.visual-exporter-chromiumA container running a headless Chromium instance configured to be accessible through WebSocket from the
visual-exporter-service, enabling the capture and export of web pages to PDF.visual-exporter-proxyA container running a proxy server (Squid Proxy) that is used by the headless Chromium instance to ensure the security of the content loaded in the browser during the PDF export process.
pdf-stapler-serviceA Kotlin-based microservice that exposes a gRPC channel for handling stapling requests. These requests include headers, footers, margin configurations, and the streamed PDF data itself. The service processes these inputs and streams back a stapled PDF as the response.
Miscellaneous
Other miscellaneous are:
dex
Dex is an OpenID Connect (OIDC) identity provider used for authentication in GoodData.CN. It is primarily used in test and development environments. Dex handles user login, token management, and identity assertions, making it a crucial component for managing access to the platform.
organization-controller
Service group responsible for managing the Panther organizations (create, update, delete). It serves as a wrapper over the Kubernetes API. Services are responsible for operations related to the custom Organization Kubernetes resource.
tools
The Tools service provides maintenance utilities for GoodData.CN, including command-line tools for interacting with the platform’s components. This service is primarily used by administrators for tasks such as troubleshooting, manual configuration, and direct interaction with the underlying infrastructure.